
본 포스팅에서는 현재 대부분의 자연어처리 모델에 사용되는 Transformer 등장 이전의 Backbone 모델인 RNN, LSTM, GRU에 대해 살펴보고 동작 방식을 이해해 보도록 하겠습니다.
1. RNN(Recurrent Neural Network)
기본적인 딥러닝 네트워크인 MLP(Multi Layer Perceptron)의 구조를 생각해 본다면, 하나의 입력 데이터에 대해 하나의 출력 결과를 내어주는 방식으로 생각해 볼 수 있다. 하지만 자연어처리에서의 텍스트 데이터는 순차적 특성을 지닌 시계열 데이터 형태이다. 이처럼 시계열적 특성을 지닌 데이터를 잘 처리할 수 있도록 고안된 모델이 RNN이며, 해당 모델에 대해 자세히 살펴보도록 하겠다.
RNN의 주요 아이디어는 고정 크기의 hidden state vector에 이전 입력의 정보들을 유지하면서 다음 출력을 위한 입력으로도 해당 hidden state vector를 사용한다. 여기서 주의할 점은 각 time step마다 서로 다른 가중치를 가진 hidden state vector를 사용하는 것이 아닌 서로 같은 파라미터를 갖는 hidden state vector를 공유한다는 점이다. 아래 그림을 살펴보면 RNN 구조를 더 쉽게 이해할 수 있을 것이다.

RNN을 표현하는 그림으로는 크게 두 가지가 있는데 그림[1]의 왼쪽처럼 입력과 출력 사이를 재귀적인 형태로 표현하는 방식과 그림[1]의 오른쪽처럼 Unrolled 형태로 펼친 방식으로 주로 설명하곤 한다. 필자는 오른쪽 그림으로 이해하는 것이 더 쉽다고 느껴진다.
위의 그림에서 볼 수 있듯이 각 time step 마다 모델은 입력으로 해당 time step의 입력 데이터와 이전 time step의 hidden state vector를 입력으로 받아 순차적으로 처리하기 때문에 시간이 지나도 이전 입력의 정보를 계속 부여받을 수 있으며 이를 통해 시계열적 특성을 보존할 수 있게 된다. 이제 수식을 통해 RNN의 동작 방식을 자세히 살펴보도록 하자.
현재 시점 $t$에서의 은닉 상태값을 $h_{t}$라고 정의해보자. 은닉층의 메모리셀은 $h_{t}$값을 계산하기 위해서 두 개의 가중치값을 가진다. 하나는 이전 시점의 은닉 상태 값인 $h_{t-1}$을 위한 $W_{h}$, 하나는 입력 값을 위한 $W_{x}$이다. 이를 식으로 표현하면 다음과 같다.
- 은닉층 : $h_{t} = tanh(W_{x}x_{t} + W_{h}h_{t-1} + b)$
- 출력층 : $y_{t} = f(W_{y}h_{t} + b)$
- 여기서 f는 풀고자 하는 task에 따라 달라진다. (e.g 이진 분류 : 시그모이드 함수, 다중 분류 : 소프트맥스 함수)
RNN의 은닉층 연산을 행렬 형태로 이해해보자. 자연어처리에서 RNN의 입력 $x_{t}$는 대부분의 경우 단어 벡터로 간주할 수 있는데, 단어 벡터 차원을 $d$라 하고, 은닉 상태의 크기를 $D_{h}$라고 했을 때, 각 벡터와 행렬의 크기는 다음과 같다.
- $x_{t}$ : ($d$ x 1)
- $W_{x}$ : ($D_{h}$ x $d$)
- $W_{h}$ : ($D_{h}$ x $D_{h}$)
- $h_{t}$ : ($D_{h}$ x 1)
- $b$ : ($D_{h}$ x 1)
배치 크기가 1이고, $d, D_{h}$ 모두 4로 가정한다면, RNN 은닉층 연산을 그림으로 표현하면 다음과 같다.

RNN에서 활성화 함수로는 주로 $tanh$ 함수를 사용한다.
그림[1]에서 볼 수 있듯이 RNN 모델의 경우 풀고자 하는 task에 따라 해당 시점에서 출력을 내보낼지 말지 결정할 수 있는데 이에 따라 one-to-one, one-to-many, many-to-one, many-to-many 방식으로 나눌 수 있다. 각각의 예시에 대해 함께 알아보도록 하자. one-to-one의 경우 우리가 알고 있는 일반적인 task이며, 입력 이미지가 주어진 경우 어떤 클래스에 해당하는지 분류하는 문제로 볼 수 있다. one-to-many의 경우 하나의 입력에 대해 다수의 출력 결과로 나타내는 것이며, Image captioning이 대표적인 예시이다. many-to-one의 경우 다수의 입력에 대해 하나의 출력 결과로 나타내는 것이며, 입력 문장에 대해 긍정인지, 부정인지를 분류하는 감정분석(Sentiment Analysis)을 예시로 들 수 있다. 마지막으로 many-to-many의 경우 다수의 입력에 대해 다수의 출력 결과로 나타내는 것이며, 예시로는 번역 task, 품사 태깅 등이 있다.
2. LSTM(Long Short Term Memory)
RNN은 순차적 흐름에 따라 역전파를 수행하는 방식은 BPTT(BackPropagation Through Time) 방식을 사용한다. 위에서 언급했듯이 RNN 모델의 활성화 함수로 $tanh$를 사용하는데 이는 출력값을 [-1, 1] 사이로 조정하기 때문에 역전파를 수행하면서 0에 가까운 값이 계속 곱해져 기울기 업데이트가 잘 되지 않는 Gradient Vanishing 문제가 발생한다. 또한 입력 시퀀스의 길이가 길어지면 이를 고정 크기의 벡터로 나타낼 때 초반 입력 부분의 정보가 손실되는 RNN 모델의 고질적인 문제인 Long term dependency 문제가 있다. LSTM은 이러한 문제를 개선시키기 위해 cell state와 gate를 사용하여 이러한 문제를 해결하였는데 LSTM의 구조와 동작 방식에 대해 자세히 살펴보도록 하자.
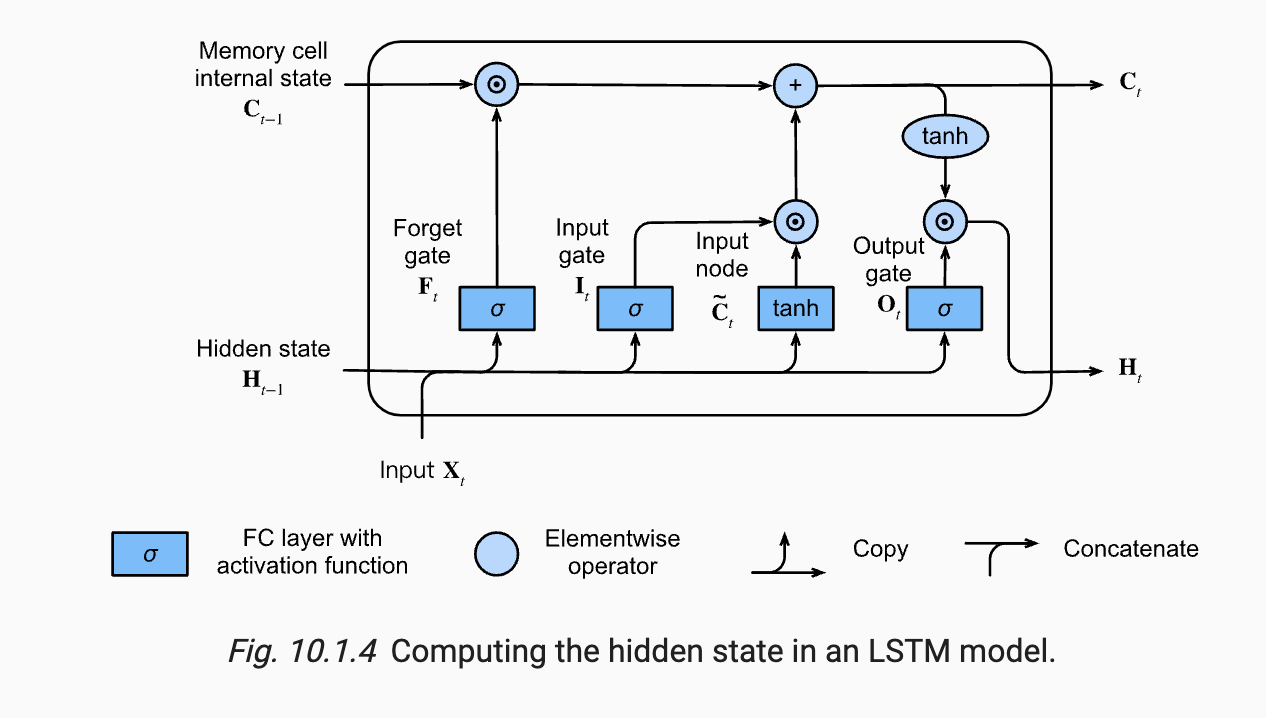
LSTM 모델의 구조는 그림[3]과 같다. 그림만 보면 굉장히 복잡해 보이지만 하나하나 살펴보면 그리 어렵지 않게 이해할 수 있으니 천천히 살펴보도록 하자. 우선 LSTM 모델의 주요 아이디어는 cell state와 hidden state를 gate와의 연산을 통해 시간의 흐름에 따라 필요한 정보만 가져가고 불필요한 정보는 버리는것이다. 모델의 출력으로는 cell state와 hidden state가 있는데 각각 $C_{t}$와 $H_{t}$로 나타낸다. cell state와 hidden state 중 cell state가 LSTM에서 핵심적인 역할을 하며 이전 입력부터 현재의 입력에 대한 정보를 담아내는 vector로 이해할 수 있다. LSTM의 동작방식에 대해 살펴보자. 우선 Forget gate는 이전 hidden state vector와 현재 입력 vector의 선형결합에 시그모이드 함수를 통해 출력 결과를 [0, 1] 사이의 값으로 변환하며 해당 출력값을 이전 cell state값에 element wise 연산을 취해서 이전 cell state 정보로부터 얼마나 버릴지를 결정하게 된다. 현재의 cell state를 계산하기 위해서는 Input gate와 Input node와의 연산이 필요하다. Input gate의 경우 현재의 입력에서 어떤 정보를 가져갈지 결정하는 역할을 하며 hidden state vector와 입력 vector의 선형결합과 시그모이드 함수를 통해 계산된다. Input node는 현재의 cell state 업데이트를 위한 후보군으로 사용되며 hidden state vector와 입력 vector의 선형결합과 $tanh$ 활성화 함수를 통해 계산된다. 이후 cell state를 업데이트하기 위해 Input node의 출력값과 Input gate의 출력값을 element wise 연산을 통한 출력값에 이전 cell state와 forget gate의 연산 결과를 더해주어서 최종적으로 cell state를 업데이트하게 된다. 마지막으로 현재 step에서의 hidden state vector를 계산하는 과정을 살펴보자. 현재 step에서의 hidden state vector를 구하기 위해서는 최종 cell state와 output gate의 연산을 통해 이루어지는데, output gate는 이전 hidden state vector와 현재 입력 vector의 선형결합에 시그모이드 함수를 씌운 결과와 최종 cell state에 $tanh$ 함수를 씌운 결과를 element wise 연산을 통해 계산되게 된다. 이렇게 계산된 최종 hidden state vector는 다음 입력의 hidden state vector로 사용되며 또한 현재 시점의 출력에 최종 hidden state vector가 사용된다. 위의 내용을 수식으로 살펴보면 다음과 같다.
- Input gate($I_{t}$) : $\sigma(W_{xi}x_{t} + W_{hi}h_{t-1} + b)$
- Forget gate($f_{t}$) : $\sigma(W_{xf}x_{t} + W_{hf}h_{t-1} + b)$
- Output gate($o_{t}$) : $\sigma(W_{xo}x_{t} + W_{ho}h_{t-1} + b)$
- Input node($\tilde{c_{t}}$) : $tanh(W_{xg}x_{t} + W_{hg}h_{t-1} + h)$
- Cell state : $f_{t}$ * $C_{t-1}$ + $I_{t}$ * $\tilde{C_{t}}$
- Hidden state : $O_{t}$ * $C_{t}$
3. GRU(Gated Recurrent Units)
GRU는 뉴욕대학교의 조경현 교수님이 개발하신 모델로 LSTM과 유사한 형태를 띠지만 gate의 개수를 줄여 연산의 효율성을 높인 모델이다. GRU 모델의 구조는 아래 그림과 같다.
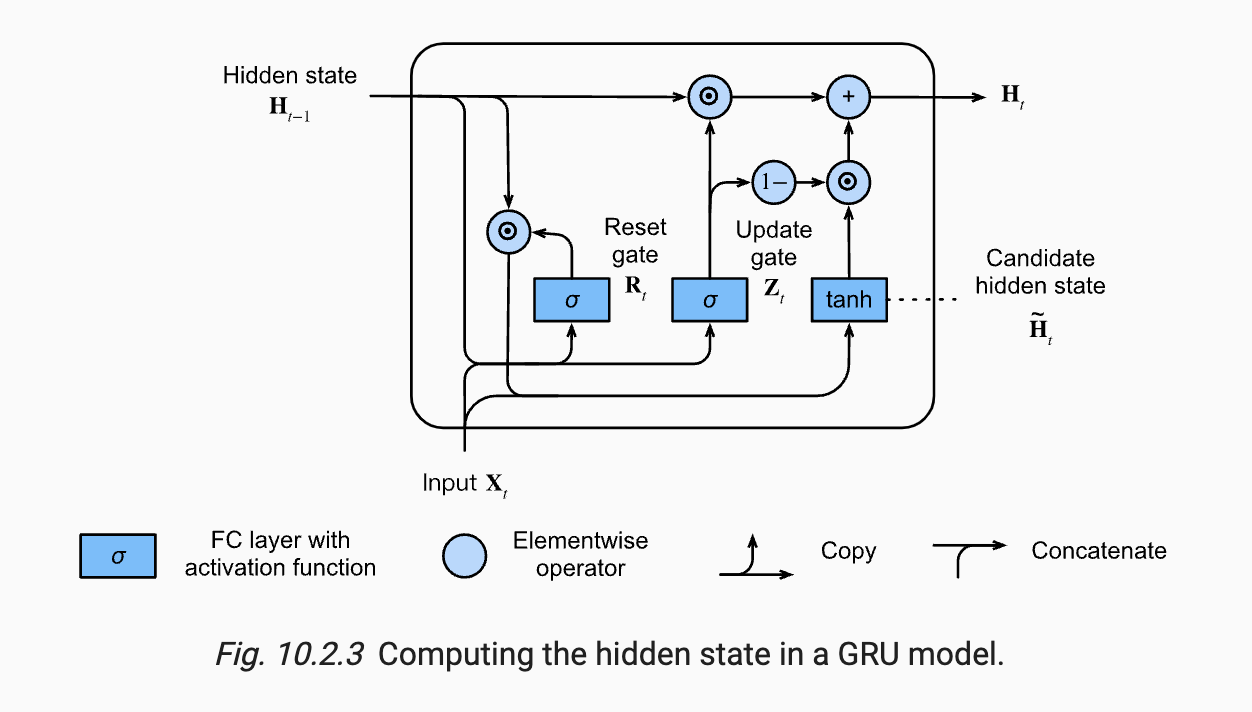
Input gate, forget gate, output gate로 구성되었던 LSTM과 달리 GRU에서는 reset gate, update gate 두 개의 gate만을 사용한다. 또한 LSTM은 출력으로 cell state와 hidden state 두 개의 출력값을 가졌는데 GRU는 hidden state 하나만을 출력으로 가지며 hidden state vector가 이전 입력부터 현재 입력까지의 정보를 담고 있는 역할을 수행한다. LSTM에서는 현재 cell state를 업데이트하기 위해 Input gate와 forget gate의 값을 사용하였지만 GRU에서는 Input gate의 역할을 update gate의 값으로, forget gate의 역할을 (1 - update gate)의 값으로 대체하여 gate 개수를 줄였다. 전체적인 흐름은 LSTM과 같으니 바로 수식을 통해 살펴보자.
- Reset gate($Z_{t}$) : $ \sigma(W_{rx}x_{t} + W_{rh}h_{t-1} + b)$
- Update gate($U_{t}$) : $ \sigma(W_{ux}x_{t} + W_{uh}h_{t-1} + b)$
- Candidate hidden state($\tilde{h_{t}}$) : $tanh(W_{hx}x_{t} + W_{hh}[R_{t}\odot h_{t-1}] + b)$
- Hidden state($H_{t}$) : $Z_{t}$ * $H_{t-1}$ + $(1 - Z_{t})$ * $\tilde{H_{t}}$
결과적으로 RNN, LSTM, GRU의 특징을 정리하면 다음과 같다.
| RNN | LSTM | GRU | |
| Gates | 0 | 3(input, forget, output) | 2(update, reset) |
| Long-term dependencies | Poor | Good | Fair |
| Vanishing & Exploding Gradient | Yes | Less | Less |
| Computational Complexity | Low | High | Medium |
'Deep Learning > NLP' 카테고리의 다른 글
| BERT와 ELECTRA 비교 (0) | 2024.03.12 |
|---|---|
| BERT와 SpanBERT 비교 (0) | 2024.03.11 |
| BERT와 RoBERTa 비교 (1) | 2024.03.11 |
| 텍스트 전처리 (0) | 2024.02.29 |
| 자연어처리 개요 (1) | 2024.02.28 |